Delivering 1 message in a Billion. Reliably and on time.

Sending billions of messages
To send and deliver 1 message in less than ten seconds amongst millions of messages getting delivered every hour is a very difficult challenge and one that we are working on improving every day.
Our mission is to facilitate conversations with your customers in real time.
The challenge arising from this mission occurs when other customers are sending large campaigns to millions of their customers at the same time you are trying to send one message to your customer.
This challenge is referred to technically as message contention. When messages are scheduled or sent through our API and user interface, they go into a message queue. At this stage, there are a lot of congestion points. In order to ensure fair sharing of the connections to carriers, our engineers work tirelessly every day so that when your recipient phone pings seconds after you click the send button. You don’t even have to think about it.
What is message contention?
Where the bottlenecks exist
Message contention is the challenge we face where we choose how to prioritise message delivery within the queue.
It begins in the contact database, passes through our scheduling and automation software layers, logging systems into message queues and onto the connections with carriers which are known as binds.
Depending on the amount of messaging traffic going out at any given time, the number of connections we maintain with different carriers increases based on demand. Each bind can carry a certain amount of outbound or inbound traffic depending on the carrier and bind type.
Scaling this connectivity is fairly simple.
What messages to send and when?
Prioritising the right message
The software algorithms that choose what messages to send and when are very intelligent and complex. What we don’t want to happen is a significant delay to a single message getting queued behind a campaign of a million messages.
For example, let’s say our system can process and queue 1000 messages per second but the carrier only delivers 300 per second. If our one message is queued behind a 1 million message campaign, then it would have to wait 55 minutes before being sent to the recipient. In a world of real time conversation, anyone that had to wait that long for a response would have moved onto another task and the engagement of the conversation would be broken.
So, how does it work?
Giving all messages a fair share of the carrier’s time
Let’s walk through an example of three customers using our system around the same time:
- Customer A sends a campaign of 1,000,000 messages at 12:00
- Customer B sends a campaign of 1,000,000 messages at 12:05
- Customer C sends a campaign of 1000 messages at 12:10
- Carriers can deliver a total of 300 messages per second
The simplest solution is to deliver messages in the order they are sent:
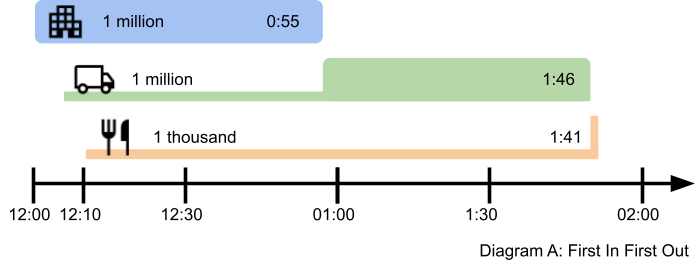
- Customer A gets 100% of the bandwidth until they finish at 12:55.
- Customer B waits until 12:55 and then gets 100% of the bandwidth until 13:51. Their last message sits there for almost 2 hours.
- Customer C only needs a tiny 3 seconds to deliver their campaign but they have to wait until 13:51 to start.
This may be simple but it is lousy for everyone except the first customer. What if we try adding a priority queue and give Customer B priority? Let’s see what that would look like:
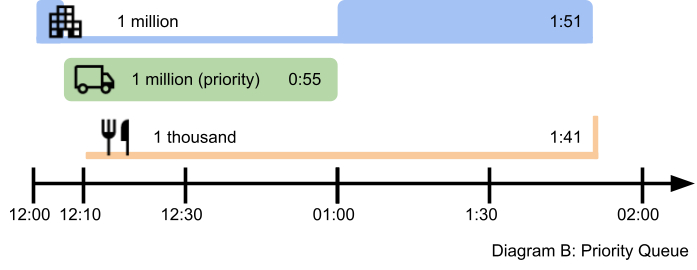
- Customer A gets 100% of the bandwidth for the first 5 minutes then pauses until 13:00.
- Customer B gets 100% of the bandwidth and finishes sooner than before.
- Customer C still has a long wait.
This lets a high priority customer “jump the queue” and can have better performance at the cost of others. What happens when multiple high priority customers use the system? Well, then we’re back to Diagram A and processing them in serial order.
Let’s try another idea. What if we allocate a percentage of the bandwidth to each customer? Surely that’s fairer. Customers A and B can have 45% each, and 10% for Customer C.
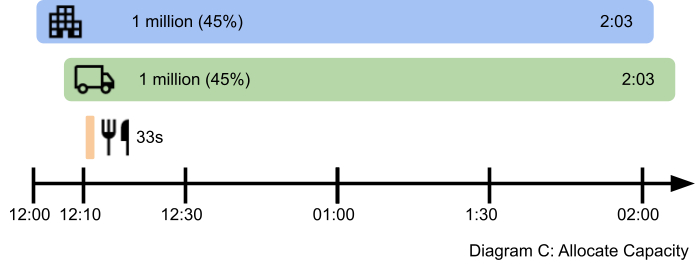
At first glance this looks good. Customers A and B take longer overall but messages start arriving on the recipient phones almost straight away. Customer C is super happy now. So, let’s roll this solution out, right? Not so fast, there are actually some serious problems:
- It’s not efficient. For the first 5 minutes the system is only operating at 45% capacity and the rest is wasted.
- It doesn’t scale well. Ideally we want to divide the capacity by the number of customers who are using it, but that changes every second and we’d have to recalculate for each one and then somehow tell all our microservices what those percentages are. Doing all that is complex and may slow down the system.
How do single messages and conversations get processed while all this is going on?
Getting all the messages to their destinations at the same time.
Fortunately, this problem has appeared before in packet switching communication networks. Take the internet for example, and how streaming video must be prioritised so that your viewing experience is smooth but still leave room for other communications such as emails, web views and file downloads to pass through. SMS isn’t that different. Up until now, we’ve been using a First In First Out (FIFO) queue. We tried adding another priority FIFO but that wasn’t much better. The answer, you’d be surprised to hear, is to add more FIFO queues. Let us introduce you to the Round Robin (RR):
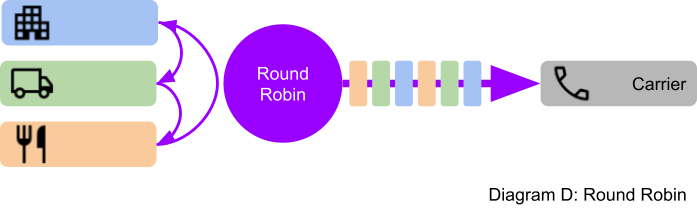
- Each customer has their own queue of messages.
- The RR pops a message from the first customer and sends it to the carrier, then moves onto the next customer, and the next until it gets to the end and then loops around.
- The carrier receives alternating messages (Customer A, B, C, A, B, C, etc.)
- The RR submits messages to the carrier at full capacity.
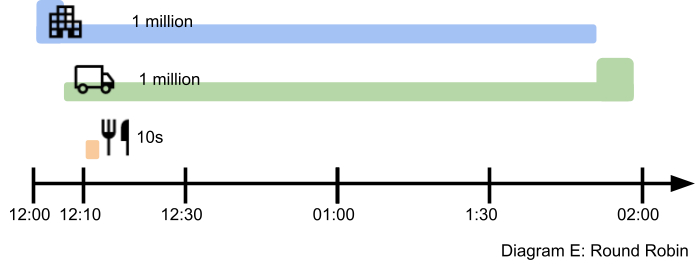
- Customer A gets 100% bandwidth for the first 5 minutes, then 50% for the remaining time.
- Customer B gets 50% bandwidth while the system is busy, then 100% at the end.
- Customer C briefly gets 33% (and so do Customer A and B) for 10 seconds.
The RR is simple, fast and fairly shares resources when all the customers have the same priority. However, to give certain customers preferential treatment in order to meet SLAs, we need a more sophisticated version of RR called the Deficit Round Robin (DRR).
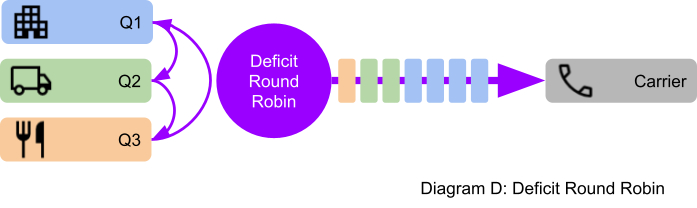
- Each customer queue has a Quantum value. We won’t go into details here except to say that the Quantum can be based on the customers SLA.
- Instead of taking one message at a time, the DRR can take multiples according to the customer’s SLA.
- Customer A (with the highest SLA) sends twice as fast as Customer B, or 4 times faster than Customer C.
There’s a lot more to it, of course, but by using a DRR we can both fairly share carrier bandwidth and prioritise customers.


